I fortunately joined the CS Ph.D. program at UC Berkeley Sky Computing Lab in the fall, 2020. I am currently working with Prof. Ion Stoica on Sky Computing over clouds, specially for AI.
I am focusing on building SkyPilot, a framework for easily and cost effectively running ML and batch jobs on any cloud, which aims to realize the Sky Computing vision. Please check out our system on Github. The paper is available in NSDI’23 and the latest paper for broker policy “Can’t Be Late” will be available in NSDI’24.
Before coming to Berkeley, I was an undergraduate student majoring in computer science at Shanghai Jiao Tong University (SJTU), a member of the SJTU ACM Honors Class, and a research intern working with Prof. Kai Yu and Prof. Yanmin Qian at SJTU SpeechLab. I also had a wonderful time as a research assistant working with Prof. Song Han at MIT HAN Lab.
News
- [2024.04] Our “Can’t Be Late” paper is appearing in NSDI’24 and won the Outstanding Paper Award.
- [2024.01] IBM Fellowship, 2023.
- [2023.04] Our SkyPilot paper is appearing in NSDI’23.
Star
- [2023.03] An open-source chatbot, Vicuna, powered by SkyPilot is released with a demo.
Star
Publications
-
|
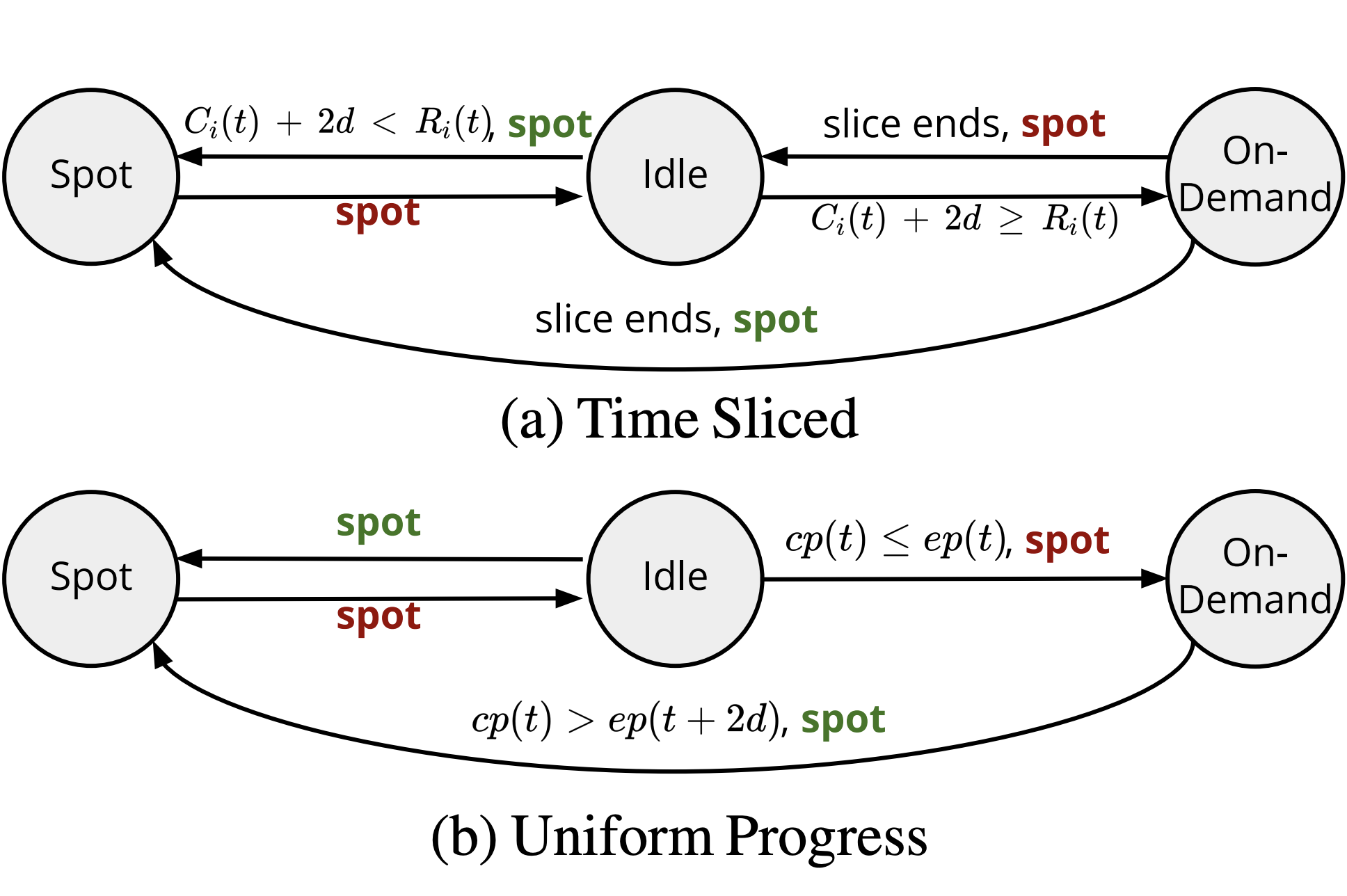
Can’t Be Late: Optimizing Spot Instance Savings under Deadlines
Zhanghao Wu,
Wei-Lin Chiang,
Ziming Mao,
Zongheng Yang,
Eric Friedman,
Scott Shenker,
and Ion Stoica
In NSDI (Outstanding Paper Award)
2024
(Outstanding Paper Award)
Abstract
|
Paper
Cloud providers offer spot instances alongside on-demand instances to optimize resource utilization. While economically appealing, spot instances’ preemptible nature causes them ill-suited for deadline-sensitive jobs. To allow jobs to meet deadlines while leveraging spot instances, we propose a simple idea: use on-demand instances judiciously as a backup resource. However, due to the unpredictable spot instance availability, determining when to switch between spot and on-demand to minimize cost requires careful policy design. In this paper, we first provide an in-depth characterization of spot instances (e.g., availability, pricing, duration), and develop a basic theoretical model to examine the worst and average-case behaviors of baseline policies (e.g., greedy). The model serves as a foundation to motivate our design of a simple and effective policy, Uniform Progress, which is parameter-free and requires no assumptions on spot availability. Our empirical study, based on three-month-long real spot availability traces on AWS, demonstrates that it can (1) outperform the greedy policy by closing the gap to the optimal policy by 2× in both average and bad cases, and (2) further reduce the gap when limited future knowledge is given. These results hold in a variety of conditions ranging from loose to tight deadlines, low to high spot availability, and on single or multiple instances. By implementing this policy on top of SkyPilot, an intercloud broker system, we achieve 27%-84% cost savings across a variety of representative real-world workloads and deadlines. The spot availability traces are open-sourced for future research.
|
-
|
LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset
Lianmin Zheng*,
Wei-Lin Chiang*,
Ying Sheng,
Tianle Li,
Siyuan Zhuang,
Zhanghao Wu,
Yonghao Zhuang,
Zhuohan Li,
Zi Lin,
Eric Xing,
Joseph E. Gonzalez,
Ion Stoica,
and Hao Zhang
In ICLR
2024
Abstract
|
Paper
Studying how people interact with large language models (LLMs) in real-world scenarios is increasingly important due to their widespread use in various applications. In this paper, we introduce LMSYS-Chat-1M, a large-scale dataset containing one million real-world conversations with 25 state-of-the-art LLMs. This dataset is collected from 210K unique IP addresses in the wild on our Vicuna demo and Chatbot Arena website. We offer an overview of the dataset’s content, including its curation process, basic statistics, and topic distribution, highlighting its diversity, originality, and scale. We demonstrate its versatility through four use cases: developing content moderation models that perform similarly to GPT-4, building a safety benchmark, training instruction-following models that perform similarly to Vicuna, and creating challenging benchmark questions. We believe that this dataset will serve as a valuable resource for understanding and advancing LLM capabilities. The dataset is publicly available at https://huggingface.co/datasets/lmsys/lmsys-chat-1m
|
-
|
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng*,
Wei-Lin Chiang*,
Ying Sheng*,
Siyuan Zhuang,
Zhanghao Wu,
Yonghao Zhuang,
Zi Lin,
Zhuohan Li,
Dacheng Li,
Eric Xing,
and others
In NeurIPS
2024
Abstract
|
Paper
|
Code
Evaluating large language model (LLM) based chat assistants is challenging due to their broad capabilities and the inadequacy of existing benchmarks in measuring human preferences.To address this, we explore using strong LLMs as judges to evaluate these models on more open-ended questions.We examine the usage and limitations of LLM-as-a-judge, including position, verbosity, and self-enhancement biases, as well as limited reasoning ability, and propose solutions to mitigate some of them.We then verify the agreement between LLM judges and human preferences by introducing two benchmarks: MT-bench, a multi-turn question set; and Chatbot Arena, a crowdsourced battle platform.Our results reveal that strong LLM judges like GPT-4 can match both controlled and crowdsourced human preferences well, achieving over 80% agreement, the same level of agreement between humans.Hence, LLM-as-a-judge is a scalable and explainable way to approximate human preferences, which are otherwise very expensive to obtain.Additionally, we show our benchmark and traditional benchmarks complement each other by evaluating several variants of LLaMA and Vicuna.The MT-bench questions, 3K expert votes, and 30K conversations with human preferences are publicly available at https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge.
|
-
|
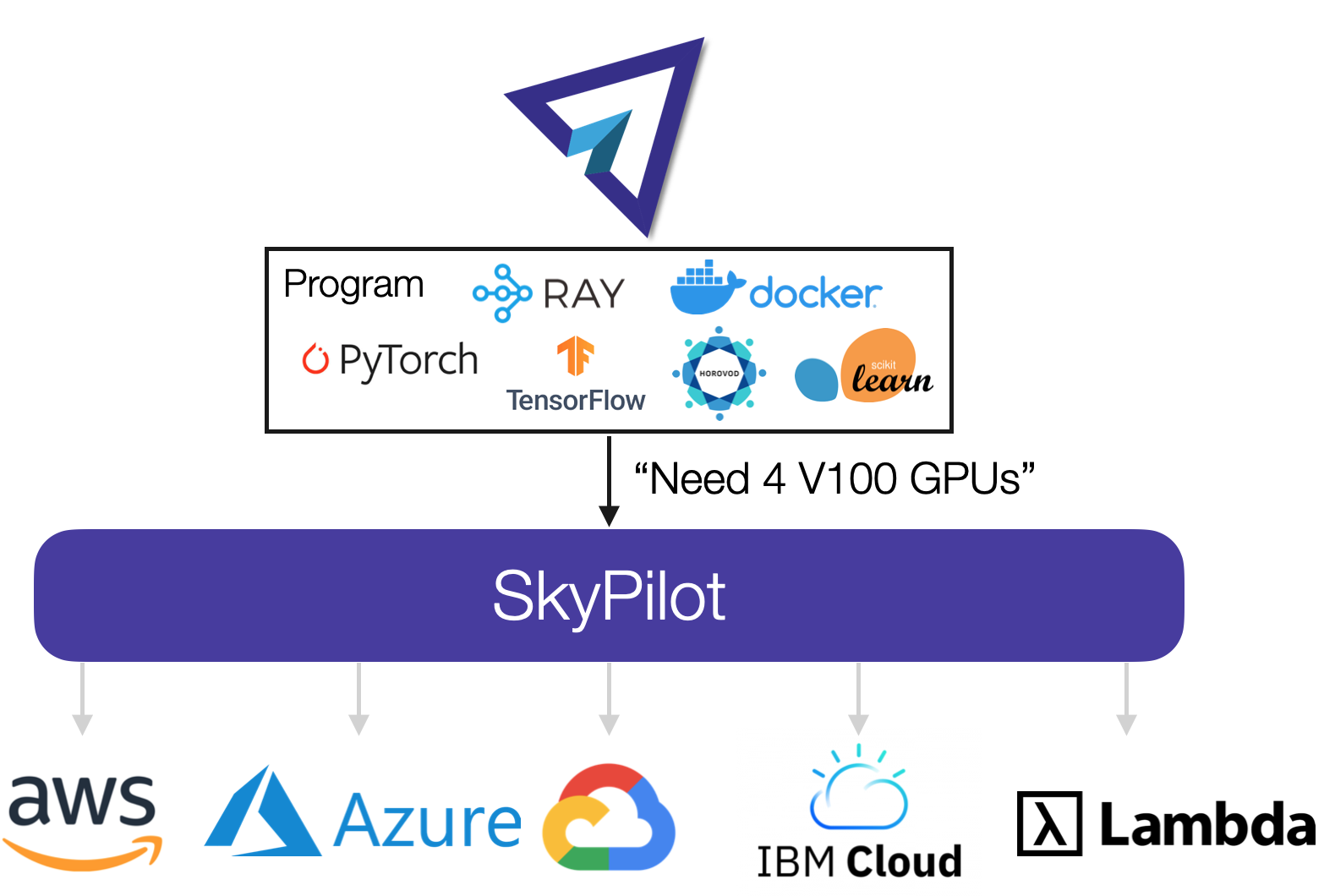
SkyPilot: An Intercloud Broker for Sky Computing
Zongheng Yang*,
Zhanghao Wu*,
Michael Luo,
Wei-Lin Chiang,
Romil Bhardwaj,
Woosuk Kwon,
Siyuan Zhuang,
Frank Sifei Luan,
Gautam Mittal,
Scott Shenker,
and Ion Stoica
In NSDI
2023
Abstract
|
Paper
|
Code
To comply with the increasing number of government regulations about data placement and processing, and to protect themselves against major cloud outages, many users want the ability to easily migrate their workloads between clouds. In this paper we propose doing so not by imposing uniform and comprehensive standards, but by creating a fine-grained two-sided market via an intercloud broker. These brokers will allow users to view the cloud ecosystem not just as a collection of individual and largely incompatible clouds but as a more integrated Sky of Computing. We describe the design and implementation of an intercloud broker, named SkyPilot, evaluate its benefits, and report on its real-world usage.
|
-
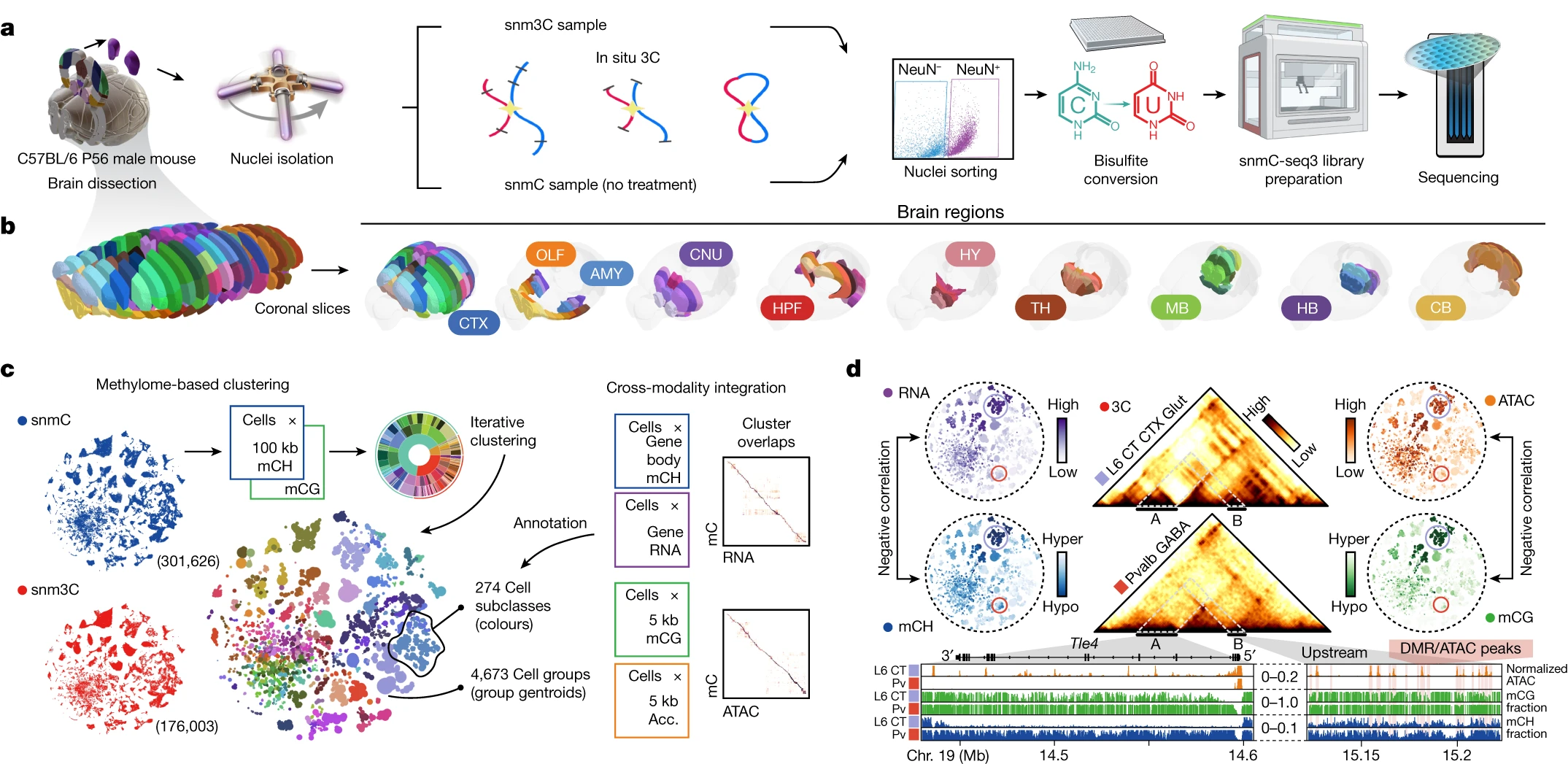
|
Single-cell DNA methylome and 3D multi-omic atlas of the adult mouse brain
Hanqing Liu,
Qiurui Zeng,
Jingtian Zhou,
Anna Bartlett,
Bang-An Wang,
Peter Berube,
Wei Tian,
Mia Kenworthy,
Jordan Altshul,
Joseph R Nery,
and others
Nature
2023
Abstract
|
Paper
Cytosine DNA methylation is essential in brain development and is implicated in various neurological disorders. Understanding DNA methylation diversity across the entire brain in a spatial context is fundamental for a complete molecular atlas of brain cell types and their gene regulatory landscapes. Here we used single-nucleus methylome sequencing (snmC-seq3) and multi-omic sequencing (snm3C-seq)1 technologies to generate 301,626 methylomes and 176,003 chromatin conformation–methylome joint profiles from 117 dissected regions throughout the adult mouse brain. Using iterative clustering and integrating with companion whole-brain transcriptome and chromatin accessibility datasets, we constructed a methylation-based cell taxonomy with 4,673 cell groups and 274 cross-modality-annotated subclasses. We identified 2.6 million differentially methylated regions across the genome that represent potential gene regulation elements. Notably, we observed spatial cytosine methylation patterns on both genes and regulatory elements in cell types within and across brain regions. Brain-wide spatial transcriptomics data validated the association of spatial epigenetic diversity with transcription and improved the anatomical mapping of our epigenetic datasets. Furthermore, chromatin conformation diversities occurred in important neuronal genes and were highly associated with DNA methylation and transcription changes. Brain-wide cell-type comparisons enabled the construction of regulatory networks that incorporate transcription factors, regulatory elements and their potential downstream gene targets. Finally, intragenic DNA methylation and chromatin conformation patterns predicted alternative gene isoform expression observed in a whole-brain SMART-seq2 dataset. Our study establishes a brain-wide, single-cell DNA methylome and 3D multi-omic atlas and provides a valuable resource for comprehending the cellular–spatial and regulatory genome diversity of the mouse brain.
|
-

|
Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality
Wei-Lin Chiang*,
Zhuohan Li*,
Zi Lin*,
Ying Sheng*,
Zhanghao Wu*,
Hao Zhang*,
Lianmin Zheng*,
Siyuan Zhuang*,
Yonghao Zhuang*,
Joseph E. Gonzalez,
Ion Stoica,
and Eric P. Xing
2023
Abstract
|
Blog
|
Demo
|
Code
We introduce Vicuna-13B, an open-source chatbot trained by fine-tuning LLaMA on user-shared conversations collected from ShareGPT. Preliminary evaluation using GPT-4 as a judge shows Vicuna-13B achieves more than 90%* quality of OpenAI ChatGPT and Google Bard while outperforming other models like LLaMA and Stanford Alpaca in more than 90%* of cases. The cost of training Vicuna-13B is around $300. The code and weights, along with an online demo, are publicly available for non-commercial use.
|
-
|
Representing Long-Range Context for Graph Neural Networks with Global Attention
Zhanghao Wu*,
Paras Jain*,
Matthew Wright,
Azalia Mirhoseini,
Joseph E. Gonzalez,
and Ion Stoica
In NeurIPS
2021
Abstract
|
Paper
|
Slides
Graph neural networks are powerful architectures for structured datasets. However, current methods struggle to represent long-range dependencies. Scaling the depth or width of GNNs is insufficient to broaden receptive fields as larger GNNs encounter optimization instabilities such as vanishing gradients and representation oversmoothing, while pooling-based approaches have yet to become as universally useful as in computer vision. In this work, we propose the use of Transformer-based self-attention to learn long-range pairwise relationships, with a novel “readout” mechanism to obtain a global graph embedding. Inspired by recent computer vision results that find position-invariant attention performant in learning long-range relationships, our method, which we call GraphTrans, applies a permutation-invariant Transformer module after a standard GNN module. This simple architecture leads to state-of-the-art results on several graph classification tasks, outperforming methods that explicitly encode graph structure. Our results suggest that purely-learning-based approaches without graph structure may be suitable for learning high-level, long-range relationships on graphs. Code for GraphTrans is available at https://github.com/ucbrise/graphtrans.
|
-

|
RLlib Flow: Distributed Reinforcement Learning is a Dataflow Problem
Eric Liang*,
Zhanghao Wu*,
Michael Luo,
Sven Mika,
Joseph E. Gonzalez,
and Ion Stoica
In NeurIPS
2021
Abstract
|
Paper
|
Slides
Researchers and practitioners in the field of reinforcement learning (RL) frequently leverage parallel computation, which has led to a plethora of new algorithms and systems in the last few years. In this paper, we re-examine the challenges posed by distributed RL and try to view it through the lens of an old idea: distributed dataflow. We show that viewing RL as a dataflow problem leads to highly composable and performant implementations. We propose RLlib Flow, a hybrid actor-dataflow programming model for distributed RL, and validate its practicality by porting the full suite of algorithms in RLlib, a widely adopted distributed RL library. Concretely, RLlib Flow provides 2-9 code savings in real production code and enables the composition of multi-agent algorithms not possible by end users before. The open-source code is available as part of RLlib at https://github.com/ray-project/ray/tree/master/rllib.
|
-
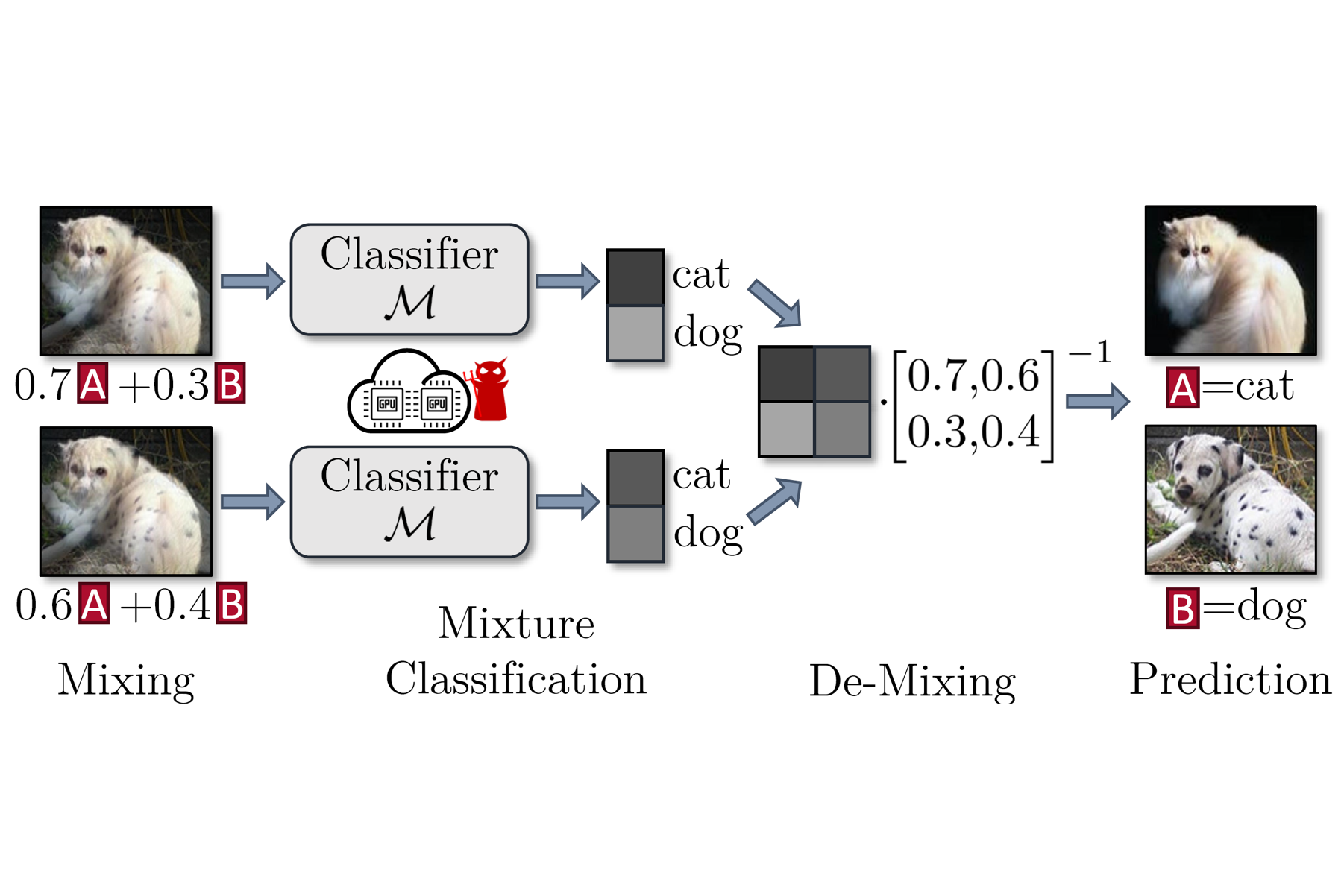
|
DataMix: Efficient Privacy-Preserving Edge-Cloud Inference
Zhijian Liu*,
Zhanghao Wu*,
Chuang Gan,
Ligeng Zhu,
and Song Han
In ECCV
2020
Abstract
|
Paper
|
Slides
|
Demo
Deep neural networks are widely deployed on edge devices. Users either perform the inference locally (i.e., edge-based) or send the data to the cloud and run inference remotely (i.e., cloud-based). However, edge devices are heavily constrained by insufficient hardware resources and cannot afford to run large models; cloud servers, if not trustworthy, will raise serious privacy issues. In this paper, we mediate between the resource-constrained edge devices and the privacy-invasive cloud servers by introducing a novel privacy-preserving edge-cloud inference framework, DataMix. We off-load the majority of the computations to the cloud and leverage a pair of mixing and de-mixing operation, inspired by mixup, to protect the privacy of the data transmitted to the cloud. Our framework has three advantages. First, it is privacy-preserving as the mixing cannot be inverted without the user’s private mixing coefficients. Second, our framework is accuracy-preserving because our framework takes advantage of the space spanned by image mixing, and we train the model in a mixing-aware manner to maintain accuracy. Third, our solution is efficient on the edge since the majority of the workload is delegated to the cloud, and mixing and de-mixing introduce few extra computations. DataMix introduces small communication overhead and maintains high hardware utilization on the cloud. Extensive experiments on multiple computer vision and speech recognition datasets demonstrate that our framework can greatly reduce the local computations on the edge (to fewer than 20% of FLOPs) with negligible loss of accuracy and no leakages of private information.
|
-
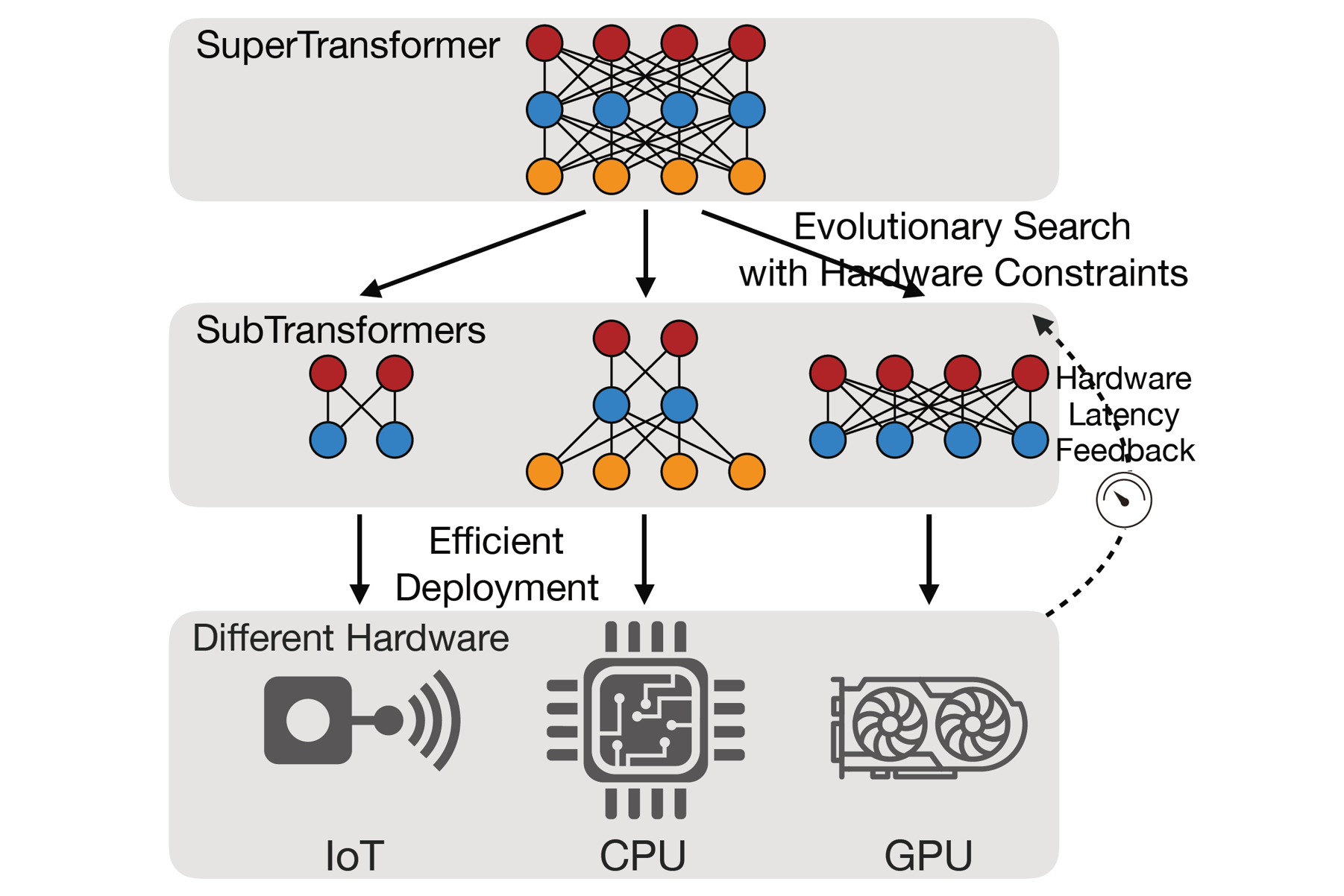
|
HAT: Hardware-Aware Transformers for Efficient Natural Language Processing
Hanrui Wang,
Zhanghao Wu,
Zhijian Liu,
Han Cai,
Ligeng Zhu,
and Song Han
In ACL
2020
Abstract
|
Paper
|
Website
Transformers are ubiquitous in Natural Language Processing (NLP) tasks, but they are difficult to be deployed on hardware due to the intensive computation. To enable low-latency inference on resource-constrained hardware platforms, we propose to design Hardware-Aware Transformers (HAT) with neural architecture search. We first construct a large design space with arbitrary encoder-decoder attention and heterogeneous layers. Then we train a SuperTransformer that covers all candidates in the design space, and efficiently produces many SubTransformers with weight sharing. Finally, we perform an evolutionary search with a hardware latency constraint to find a specialized SubTransformer dedicated to run fast on the target hardware. Extensive experiments on four machine translation tasks demonstrate that HAT can discover efficient models for different hardware (CPU, GPU, IoT device). When running WMT’14 translation task on Raspberry Pi-4, HAT can achieve 3× speedup, 3.7× smaller size over baseline Transformer; 2.7× speedup, 3.6× smaller size over Evolved Transformer with 12,041× less search cost and no performance loss. HAT code is open-sourced at https://github.com/mit-hanlab/hardware-aware-transformers.git.
|
-

|
Lite Transformer with Long-Short Range Attention
Zhanghao Wu*,
Zhijian Liu*,
Ji Lin,
Yujun Lin,
and Song Han
In ICLR
2020
Abstract
|
Paper
|
Slides
|
Website
Transformer has become ubiquitous in natural language processing (e.g., machine translation, question answering); however, it requires enormous amount of computations to achieve high performance, which makes it not suitable for mobile applications that are tightly constrained by the hardware resources and battery. In this paper, we present an efficient mobile NLP architecture, Lite Transformer to facilitate deploying mobile NLP applications on edge devices. The key primitive is the Long-Short Range Attention (LSRA), where one group of heads specializes in the local context modeling (by convolution) while another group specializes in the long-distance relationship modeling (by attention). Such specialization brings consistent improvement over the vanilla transformer on three well-established language tasks: machine translation, abstractive summarization, and language modeling. Under constrained resources (500M/100M MACs), Lite Transformer outperforms transformer on WMT’14 English-French by 1.2/1.7 BLEU, respectively. Lite Transformer reduces the computation of transformer base model by 2.5x with 0.3 BLEU score degradation. Combining with pruning and quantization, we further compressed the model size of Lite Transformer by 18.2x. For language modeling, Lite Transformer achieves 1.8 lower perplexity than the transformer at around 500M MACs. Notably, Lite Transformer outperforms the AutoML-based Evolved Transformer by 0.5 higher BLEU for the mobile NLP setting without the costly architecture search that requires more than 250 GPU years. Code has been made available at https://github.com/mit-han-lab/lite-transformer.
|
-

|
On-Device Image Classification with Proxyless Neural Architecture Search and Quantization-Aware Fine-Tuning
Han Cai,
Tianzhe Wang,
Zhanghao Wu,
Kuan Wang,
Ji Lin,
and Song Han
In ICCV workshop
2019
Abstract
|
Paper
|
Slides
It is challenging to efficiently deploy deep learning models on resource-constrained hardware devices (e.g., mobile and IoT devices) with strict efficiency constraints (e.g., latency, energy consumption). We employ Proxyless Neural Architecture Search (ProxylessNAS) to auto design compact and specialized neural network architectures for the target hardware platform. ProxylessNAS makes latency differentiable, so we can optimize not only accuracy but also latency by gradient descent. Such direct optimization saves the search cost by 200x compared to conventional neural architecture search methods. Our work is followed by quantization-aware fine-tuning to further boost efficiency. In the Low Power Image Recognition Competition at CVPR’19, our solution won the 3rd place on the task of Real-Time Image Classification (online track).
|
-
|
Data Augmentation Using Deep Generative Models for Embedding Based Speaker Recognition
Shuai Wang,
Yexin Yang,
Zhanghao Wu,
Yanmin Qian,
and Kai Yu
IEEE/ACM Transactions on Audio, Speech, and Language Processing
2020
Abstract
|
Paper
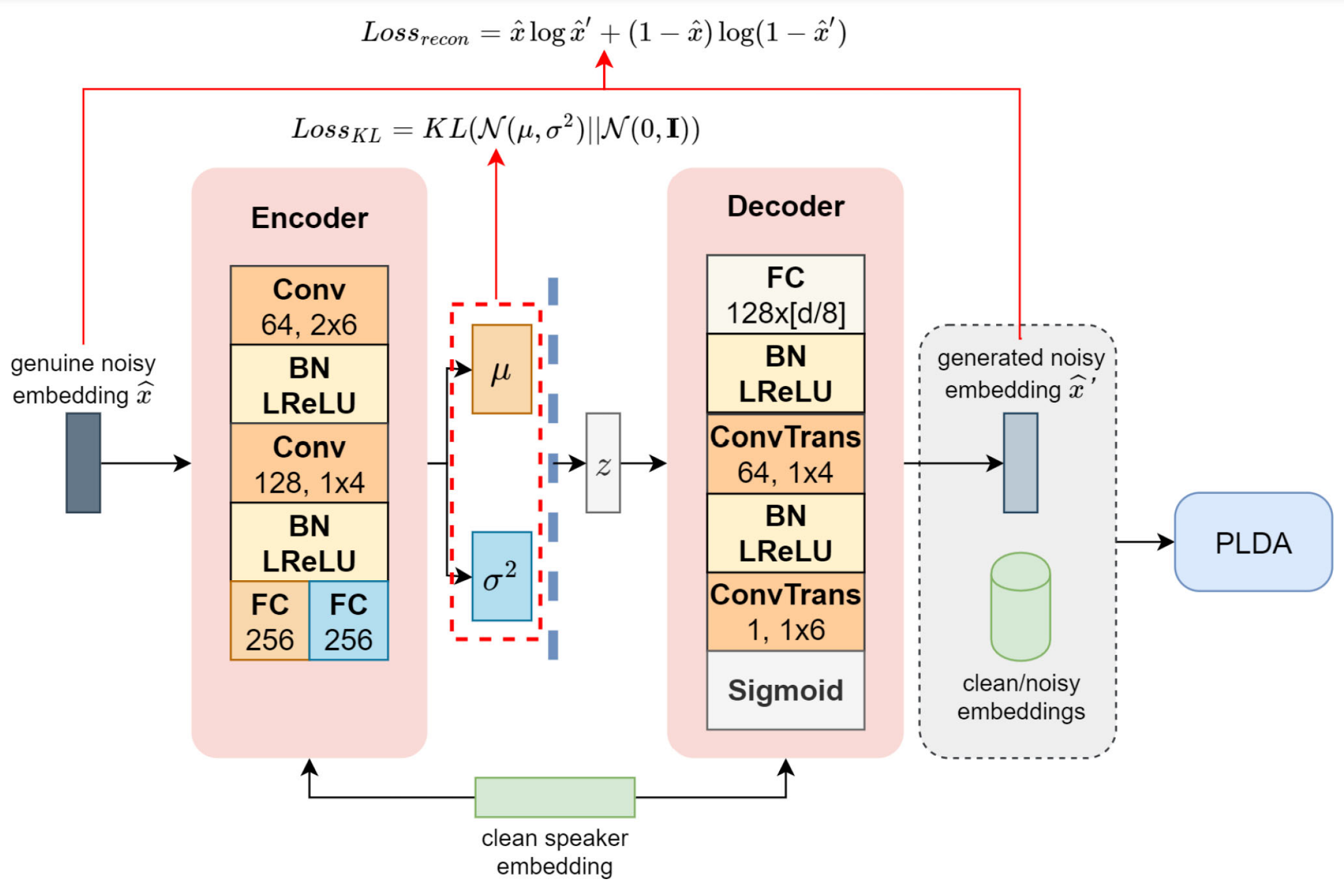
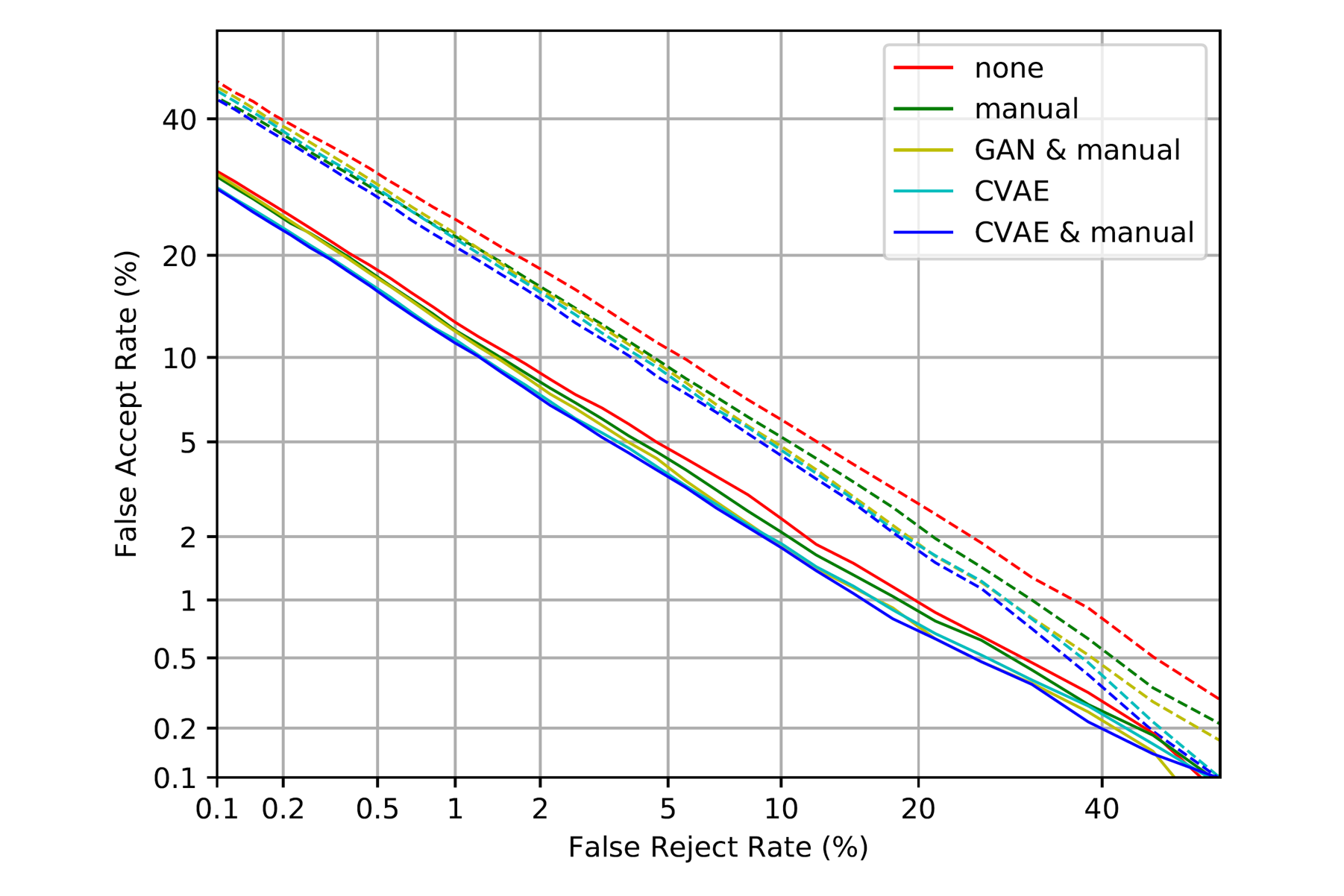
Data augmentation is an effective method to improve the robustness of embedding based speaker verification systems, which could be applied to either the front-end speaker embedding extractor or the back-end PLDA. Different from the conventional augmentation methods such as manually adding noise or reverberation to the original audios, in this article, we propose to use deep generative models to directly generate more diverse speaker embeddings, which would be used for robust PLDA training. Conditional GAN, and VAE are designed, and investigated for different embedding types, including factor analysis based i-vector, TDNN based x-vector, and ResNet based r-vector. The proposed back-end augmentation methods are evaluated on NIST SRE 2016, and 2018 dataset. Within the popular x-vector, and r-vector framework, the experimental results show that our proposed methods can outperform the traditional audio based back-end augmentation method while different front-end augmentation methods are considered.
|
-
|
Data Augmentation Using Variational Autoencoder for Embedding Based Speaker Verification
Zhanghao Wu,
Shuai Wang,
Yanmin Qian,
and Kai Yu
In Interspeech
2019
(Oral)
Abstract
|
Paper
|
Slides
Domain or environment mismatch between training and testing, such as various noises and channels, is a major challenge for speaker verification. In this paper, a variational autoencoder (VAE) is designed to learn the patterns of speaker embeddings extracted from noisy speech segments, including i-vector and xvector, and generate embeddings with more diversity to improve the robustness of speaker verification systems with probabilistic linear discriminant analysis (PLDA) back-end. The approach is evaluated on the standard NIST SRE 2016 dataset. Compared to manual and generative adversarial network (GAN) based augmentation approaches, the proposed VAE based augmentation achieves a slightly better performance for i-vector on Tagalog and Cantonese with EERs of 15.54% and 7.84%, and a more significant improvement for x-vector on those two languages with EERs of 11.86% and 4.20%.
|
Education
Honors & Award
- Outstanding Paper Award, in NSDI’24, 2024.
- IBM Fellowship, 2024.
- 1st place, in Visual Wake Words (VWW) Challenge of CVPR’19, 2019.
- 3rd place, in Low Power Image Recognition Challenge of CVPR’19 (1st place of academic groups), 2019.
- Outstanding Winner,in Mathematical Contest in Modeling (top 0.5%), 2017.
- Chinese National Scholarship, highest honor for undergraduates, top 0.2% nation wide, 2018 & 2019.
- Excellent Graduate Award of SJTU, the highest honor for graduates at SJTU, 2020.
- Zhiyuan Outstanding Student Scholarship of SJTU, 16 graduates of SJTU Zhiyuan College, 2020.
- Fan Hsu-Chi Chancellor’s Scholarship, top 0.1%of 17,000 students in SJTU, 2017.
- Zhiyuan Honorary Scholarship, top 5% of 17,000 students in SJTU, 2016-2018.



